Kaggle House Price Prediction
Before Start Link to heading
This project comes from an assignment I did during my Master’s at Queen’s University. I’m using this post to document the data analysis I did, but in simpler terms compared to our final report. The goal is to make it easier to understand and to build a reference for future data problems I might encounter. Big thanks to my teammates for their support throughout this project!
Introduction Link to heading
As team assignment, we joined the House Prices competition on Kaggle, and we were using the programming language R to build a model and a combination of explantory variables describing residential homes in Ames, lowa to predict the final purchse price in this market.
We finally spent 1 week on this project and achieved top 30% (rank of 1239 out of 4220 teams) with our final submission.
The following steps were used:
- data exploration
- data cleaning
- data modelling
- model revision
- [feature engineering]
Data Exploration Link to heading
We used descriptive data analysis, such as histogram, boxplot, min, median, max, correlation to understand the relationship between variables. After analyzation, we selected 13 variables (out of 80) to build our preditive model. ) Y-variable
- Salesprice: sales price in dollars
X-variables
- GrLivArea: above grade (ground) living area
- OverallQual: rate the overall material and finish the house
- Neighborhood: physical locations with Ames city limits
- Condition1: proximity to main road or railroad
- YearBuilt: year built (original construction date)
- YearRemodAdd: year of remodel
- Yrbltremdiff: YearRemodAdd - YearBuilt (feature engineered difference between year of remodel and year built)
- Garagecars: # of cars that can fit in the garage
- MoSold: month sold
- YearSold: year sold
- MSZoning: type of sale
- SaleCondition: condition of sale
Here are some data visualizations output:
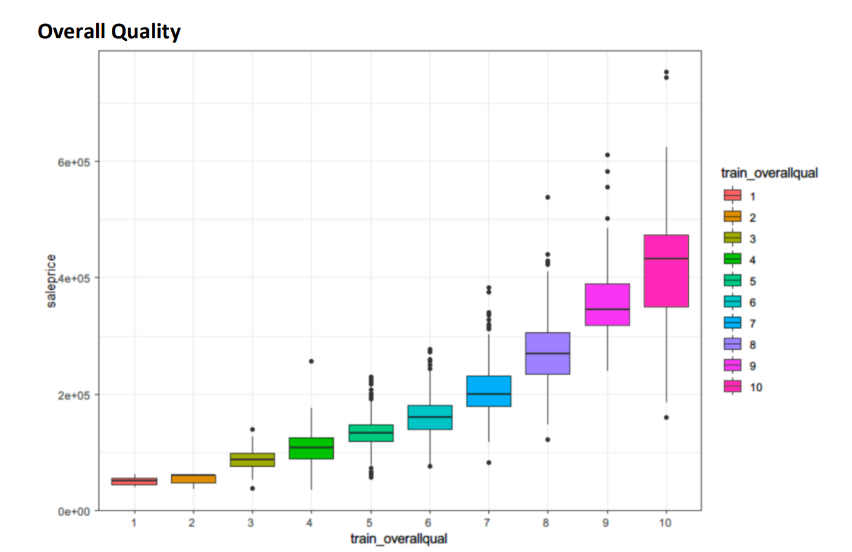
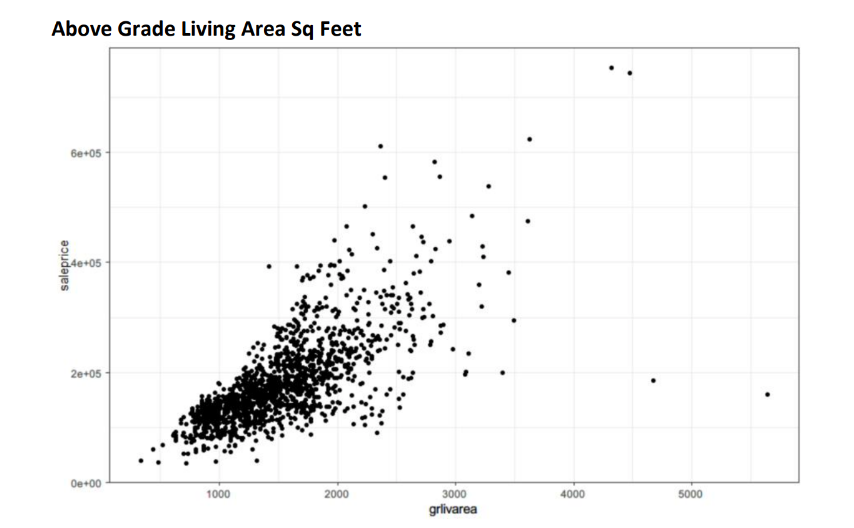
Data Cleaning Link to heading
Based on the work conduted in data exploration, the priority of data cleaning was to determine the appropriate way to:
- Treat missing data with a value of NA
- Treat data with a value of zero
Dropping Columns Link to heading
To increased data cleaning effectiveness, I wrote a function missing_value to identify the number and proportion of NA’s and the number and proportion of integer values of zero.
here is the missing_value code:
missing_value<-function(df){
len<-length(df[,1])
m<-data.frame(
class=sapply(df,class),
na=colSums(is.na(df)),
zero=colSums(df==0,na.rm=T)
)
m$na_prop <- paste(round(m$na/len*100,2),"%")
m$zero_prop <- paste(round(m$zero/len*100,2),"%")
m2 <- subset(m,rowSums(m[,2:3])!=0)
m2<-m2[order(-m2$na,-m2$zero),]
return(m2)
}
Columns with over 15% missing or zero values were dropped due to insufficient data for accurate imputation or prediction. A high proportion of zeros indicated the absence of a feature in most homes, making it unlikely to influence the model. The 15% cutoff was chosen because higher proportions of missing or zero values were unlikely to add predictive value. Additionally, columns within the same category (e.g., Garage or Basement) were simplified by retaining only one representative variable, dropping the others to streamline the model.
Imputation Link to heading
For the remainder of the columns that were kept, imputation was conducted to replace NA values.
General Cases
- For categorical values, a for loop was used to replace the NA values with the mode.
- For numerical values, a for loop was used to the NA values with the median.
Specific Cases
- Lotfrontage: MS Zoning was grouped, and the median lot frontage was calculated for each zone. The median value for each zone replaced NA values.
- Masvnrtype: For the masonry veneer type, if the value was NA, replace it with None.
- Masvnrarea:
- For the masonry veneer area, if the masonry veneer type was NA, replace it with None
- Each masonry veneer type median area was calculated, and NA values were replaced with the median values for each type.
Data Modelling Link to heading
Preparation for modelling was conducted as follows:
- As data exploration revealed skewness in the data, the natural log of the y variable sale price was taken
- Model.matrix() was used to create a new dataset X after removing the intercept to create a model matrix
- Data was split into train and test data set
Lasso Regression Link to heading
- The glmnet package was used to build a lasso model with 10-fold cross-validation to determine the optimal lambda.
- The optimal lambda, resulting in the lowest mean squared error within the confidence interval, was selected for the final model.
- The lasso model’s coefficients were read, and predictions on the test data were made using exp(predict()) to account for the initial log transformation of the sales price variable.
Ridge Regression Link to heading
- The glmnet package was used to build a ridge model with alpha = 0.
- 10-fold cross-validation determined the optimal lambda for the model by selecting the lambda with the lowest mean squared error.
- Coefficients were read, and test data predictions were made using exp(predict()) due to the log transformation of the sales price.
Model Revision - Second Iteration Link to heading
Two different methods were utilized to improve the model:
- Data cleaning: It was inferred that the data could be better cleaned to produce a better result
- Feature engineering: It was inferred that certain features could be produced to create a better result
Revisit Data Cleaning Link to heading
In the first iteration, we dropped over thirty variables with more than 15% NA or zero values. To improve the model by retaining more original data, we increased the threshold to 50% in the second iteration. This reduced the dropped columns to ten. We used ridge and lasso regression to minimize bias from our initial selection, with ridge pushing unnecessary coefficients close to zero and lasso removing them entirely.
here are drop values:
- poolqc
- poolarea
- miscfeature
- miscval
- alley
- fence
- 3ssnporch
- screenporch
- enclosedporch
- openporchsf